
Drug-induced liver injury (DILI) is a significant concern in drug discovery, in particular because it might only be observed late in large clinical studies, after
Category: Jupyter Notebook
In a previous post I illustrated how to download PubChem and create a local searchable database using a Jupyter notebook. I also included a vortex/python
PubChem is an invaluable source of information about 99 million molecules accessible via a website or programmatically. PubChem is an open chemistry database at the National Institutes
Rowan is a software platform that makes it possible to run high-level quantum chemical calculations through a web interface. In general, running quantum chemical calculations
TabPFN is a foundation model trained on around 130,000,000 synthetically generated datasets that mimic “real world” tabular data. These datasets sampled dataset size and number
A very nice review of generative models for molecular design from Morgan Thomas. https://cheminformantics.blogspot.com/2024/12/structure-aware-generative-molecular.html Includes Jupyter notebooks for data and analysis.
I just stumbled across this and thought I’d flag it. VeloxChem is a Python-based open source quantum chemistry software developed for the calculation of molecular
A really interesting preprint caught my attention from Connor Coley’s group at MIT. ShEPhERD diffusing shape, electrostatics, and pharmacophores for bioisosteric drug design https://arxiv.org/abs/2411.04130v1 …
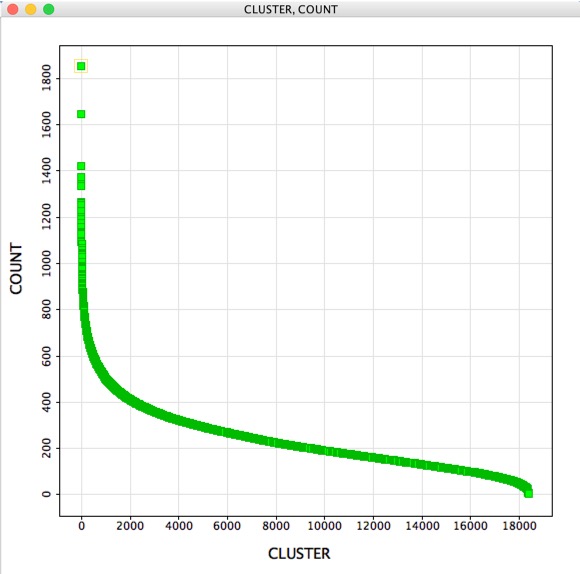
Clustering is an invaluable cheminformatics technique for subdividing a typically large compound collection into small groups of similar compounds. One of the advantages is that
tmap is a very fast visualisation library for large, high-dimensional data sets. It was published in 2020 DOI and the code is available on GitHub