Whilst most of the Vortex scripts mentioned on this site to date involve chemical structures we should not forget that Vortex is an excellent general data analytics tool and the data set does not have to include any molecular structures. Recently I was asked about the number of publications associated with a particular potential therapeutic target and it struck me that Vortex might actually be an excellent tool to investigate this.
PubMed
PubMed comprises more than 24 million citations for biomedical literature from MEDLINE, life science journals, and online books. Citations may include links to full-text content from PubMed Central and publisher web sites. They also provide a number of programming tools that allow access to the information, E-utilities are a set of server-side programs that provide a stable interface into the Entrez query and database system.
To access these data, a piece of software first posts an E-utility URL to NCBI, then retrieves the results of this posting, after which it processes the data as required. The software can thus use any computer language that can send a URL to the E-utilities server and interpret the XML response; examples of such languages are Perl, Python, Java, and C++.
Updated
If you regularly use the E-utilities API you might want to read this.
After May 1, 2018, NCBI will limit your access to the E-utilities unless you have one of these keys. Obtaining an API key is quick, and simple, and will allow you to access NCBI data faster. If you don’t have an API key, E-utilities will still work, but you may be limited to fewer requests than allowed with an API key.
After May 1, 2018, any computer (IP address) that submits more than 3 E-utility requests per second will receive an error message. This limit applies to any combination of requests to EInfo, ESearch, ESummary, EFetch, ELink, EPost, ESpell, and EGquery.
If you write software of scripts that access the E-utilities API then the users will need to get their own api key. Calls will have this format
https://www.ncbi.nlm.nih.gov/entrez/eutils/einfo.fcgi?db=pubmed&api_key=ABCD123
I’ve updated this script to reflect this change, and I’ve highlighted where you need to add your api key in the script. I’ve also tried to ensure that any query string should be encoded to make it URL safe. I’ve also extended the search range up to 2018.
Text based searches use esearch.fcgi and has the format shown below, this query searches for “BRD2” between 2010 and 2014.
http://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&term=BRD2[All]+AND+2010/01/01[pdat]:2014/12/31[pdat]
The results are returned in XML format
<eSearchResult>
<Count>85</Count>
<RetMax>20</RetMax>
<RetStart>0</RetStart>
<IdList>
<Id>25467295</Id>
<Id>25249180</Id>
<Id>25247679</Id>
<Id>25194491</Id>
<Id>25130458</Id>
<Id>25049379</Id>
<Id>25036774</Id>
<Id>25001387</Id>
<Id>24979794</Id>
<Id>24924589</Id>
<Id>24906137</Id>
<Id>24905006</Id>
<Id>24811781</Id>
<Id>24759736</Id>
<Id>24741066</Id>
<Id>24733848</Id>
<Id>24695857</Id>
<Id>24632969</Id>
<Id>24623816</Id>
<Id>24595446</Id>
</IdList>
<TranslationSet/>
<TranslationStack>
<TermSet>
<Term>BRD2[All]</Term>
<Field>All</Field>
<Count>164</Count>
<Explode>N</Explode>
</TermSet>
<TermSet>
<Term>2010/01/01[PDAT]</Term>
<Field>PDAT</Field>
<Count>0</Count>
<Explode>N</Explode>
</TermSet>
<TermSet>
<Term>2014/12/31[PDAT]</Term>
<Field>PDAT</Field>
<Count>0</Count>
<Explode>N</Explode>
</TermSet>
<OP>RANGE</OP>
<OP>AND</OP>
</TranslationStack>
<QueryTranslation>BRD2[All] AND 2010/01/01[PDAT] : 2014/12/31[PDAT]</QueryTranslation>
</eSearchResult>
Where “Count” gives the number of publications within the date range.
Searching PubChem from Vortex
Bromodomains are 110 amino acid protein domains that recognise acetyl lysine residues such as those on the N-terminal tails of histones. This recognition is often a prerequisite for protein-histone association and chromatin remodelling and is an area of great current interest in oncology. An increasing number of bromodomains have now been identified and are detailed below. When starting a project it is often interesting to know how many publications there are for a particular target and whether they are increasing or decreasing over time.
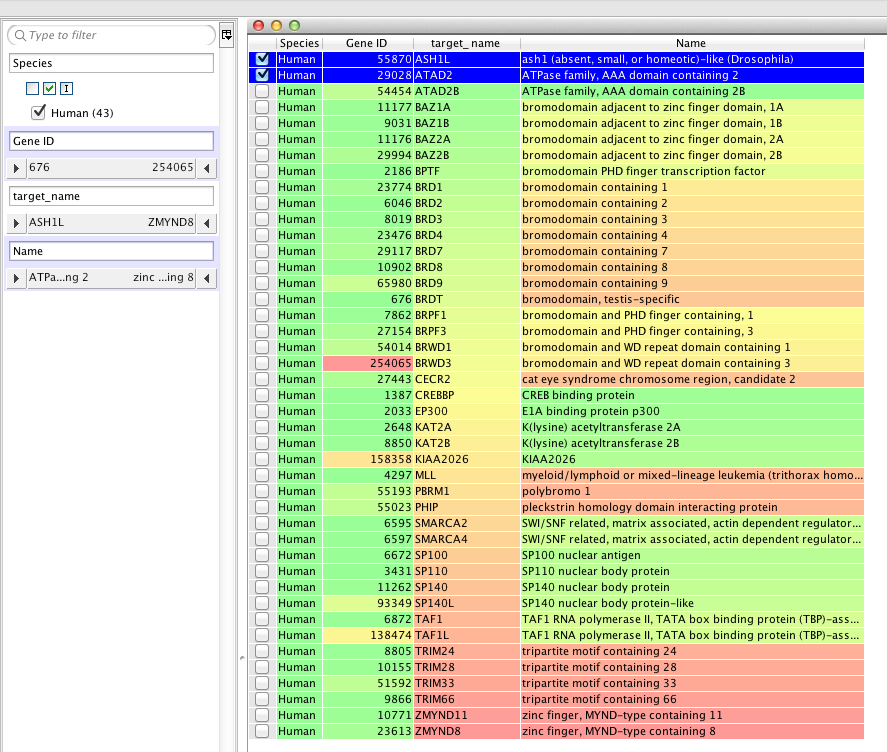
**First you will need to add your api key into the script**. The next part of the script allows the user to select the column that contains the query term.
#replace ********* with your apikey
apikey = "&api_key=*********"
input_label = swing.JLabel("Search term column (for input)")
input_cb = workspace.getColumnComboBox()
panel = swing.JPanel()
layout.fill(panel, input_label, 0, 0)
layout.fill(panel, input_cb, 1, 0)
ret = vortex.showInDialog(panel, "Choose search term column")
input_idx = input_cb.getSelectedIndex()
col = vtable.getColumn(input_idx - 1)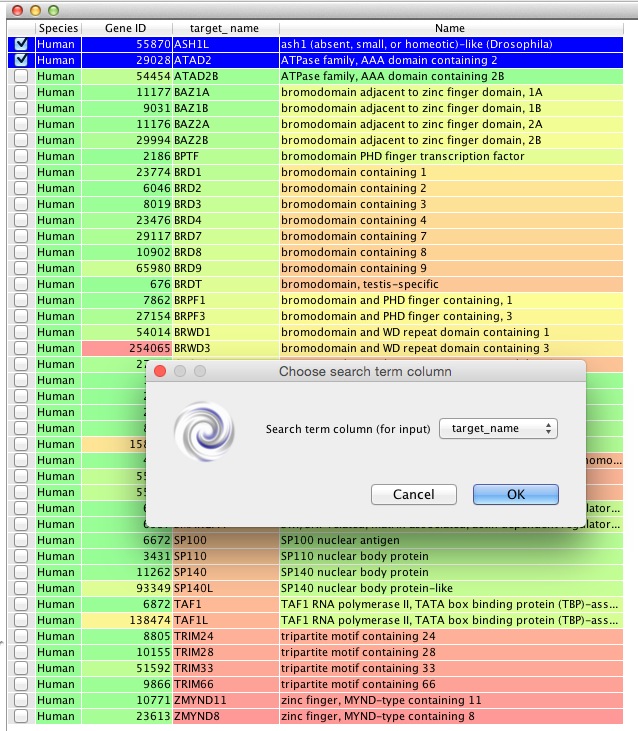
The next part of the script runs through each row of the workspace gets the search query term, converts it to a HTML safe format, and constructs the URL (including the date range) to search PubMed, including the api key. The response XML is then parsed to extract count of publications and the table updated.
rows = vtable.getRealRowCount()
for r in range(0, int(rows)):
targetID = col.getValueAsString(r)
targetID = urllib.quote(targetID, safe='')
mystr2000 = "http://eutils.ncbi.nlm.nih.gov/entrez/eutils/esearch.fcgi?db=pubmed&term=" + targetID + "[All]+AND+2000/01/01[pdat]:2000/12/31[pdat]" + apikey
response = urllib2.urlopen(mystr2000)
xmlstring = response.read()
root = etree.fromstring(xmlstring)
TheScore = str(root.find('Count').text)
col2000.setValueFromString(r, TheScore)
vtable.fireTableStructureChanged()
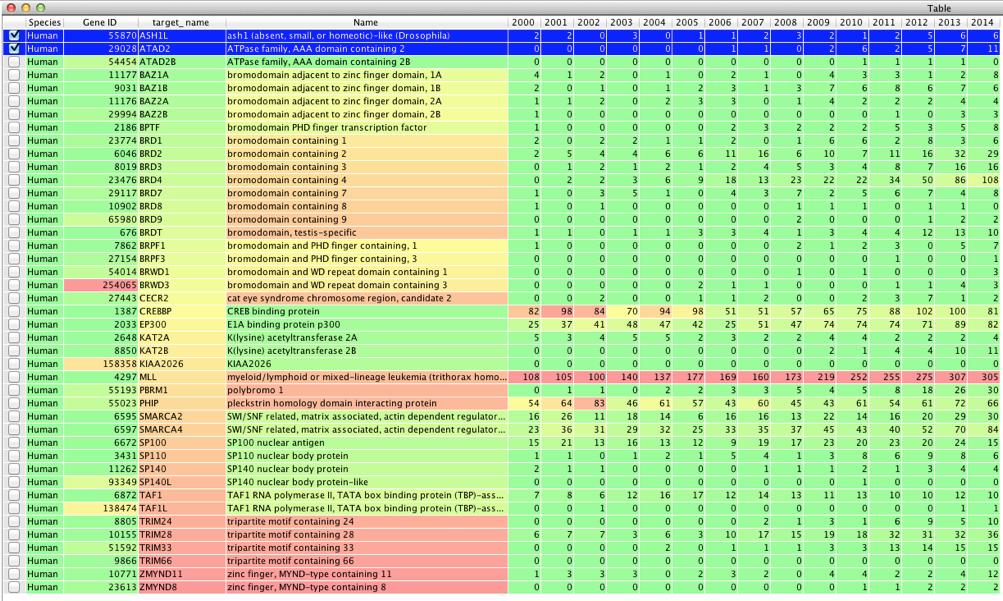
Whilst this is an obvious way to summarise data in a table it is not ideal from the point of view of plotting the data in Vortex. In order to create a plot we need the data to be in two columns (to provide the x and y axes), so we need “de-pivot” the data, and fortunately there is already an example script provided by Matt Ironside at Dotmatics.
People are probably more familiar with the term “Pivot Table“, this is a process implemented in many spreadsheet applications that allows the user to summarise data contained in long flat tables.
In this case we need to do the reverse, convert the summarised data into a long simple table. First we get all the column names then identify the index columns that will be used in the new workspace, then the columns that will be “de-pivoted”
columnNames = vtable.getColumnNames(0)
cols = []
includeCols = []
pivotCols = []
for name in columnNames:
cols.append(name)
# We may need to convert mol files to smiles
mfm = vtable.getMolFileManager()
# Prompt user for list of inhibition values to de-pivot
content = javax.swing.JPanel()
duallist = components.VortexDualList()
duallist.setItems(cols, None)
layout.fill(content, duallist, 0, 0)
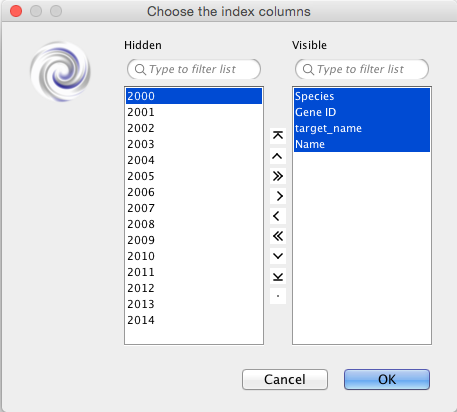
ret = vortex.showInDialog(content, "Choose the index columns")
if ret == vortex.OK:
for i in duallist.getItems():
includeCols.append(cols[i])
for col in includeCols:
cols.remove(col)
if not len(includeCols):
vortex.alert("No index columns selected")
sys.exit(0)
# Choose some columns to depivot
content = javax.swing.JPanel()
duallist = components.VortexDualList()
duallist.setItems(cols, None)
layout.fill(content, duallist, 0, 0)
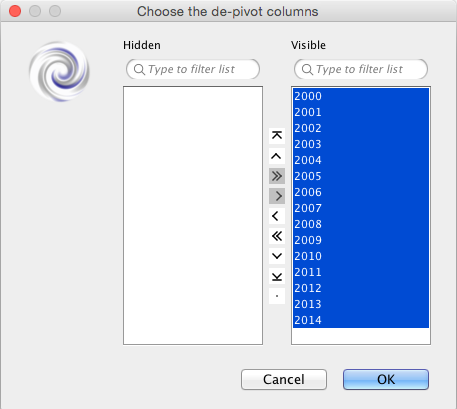
ret = vortex.showInDialog(content, "Choose the de-pivot columns")
if ret == vortex.OK:
for i in duallist.getItems():
pivotCols.append(cols[i])
if not len(pivotCols):
vortex.alert("No de-pivot columns selected")
sys.exit(0)
The user is asked to select the index columns and use the “>” to move them across.
# Now create a temp csv file with de-pivoted data
tmpfile = com.dotmatics.vortex.Vortex.getVortex().getTempFile('csv')
f = open(tmpfile, "w")
# Write the column headers
for col in includeCols:
if col == "Structure":
f.write("Smiles,")
else:
f.write(col + ",")
f.write("Year,Number\n")
# Copy the values across
for r in range(0, vtable.getRealRowCount()):
for pivotCol in pivotCols:
if vtable.getValueAt(r,vtable.getColumnId(pivotCol)) is not None:
for col in includeCols:
value = ""
if col == "Structure":
value = vortex.getMolProperty(mfm.getMolFileAtRow(r), 'SMILES')
else:
value = vtable.getColumn(col, True).getValueAsString(r)
# Strip any commas from the value string otherwise they will upset
# the CSV file
f.write(value.replace(",","") + ",")
f.write(pivotCol + ",")
f.write(str(vtable.getValueAt(r,vtable.getColumnId(pivotCol))) + "\n")
f.close()
# Load in the CSV file as a new table, plotting a graph of "Year" against "Number"
t = com.dotmatics.vortex.table.VortexTableModel.readCSV(tmpfile, True, ',', '"')
fieldCol = t.getColumnId("Year")
valueCol = t.getColumnId("Number")
vortex.addTable('Depivoted data', t, fieldCol, valueCol, -1, False)
# Join the workspaces on the Gnumber column
t.setJoinColumn(t.getColumn(includeCols[0], True))
vtable.setJoinColumn(vtable.getColumn(includeCols[0], True))
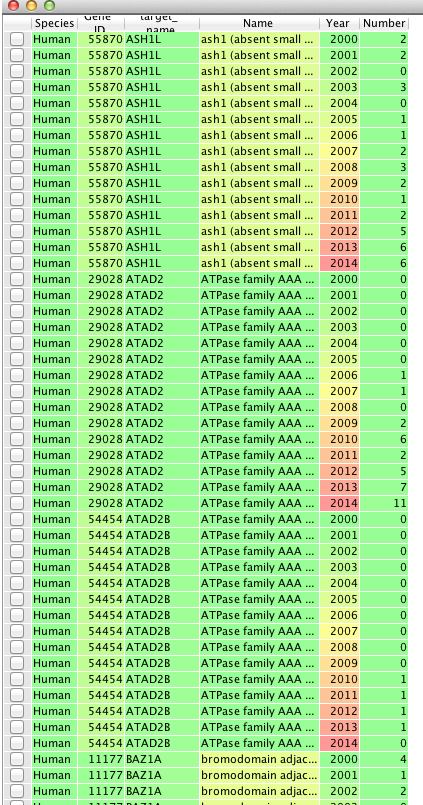
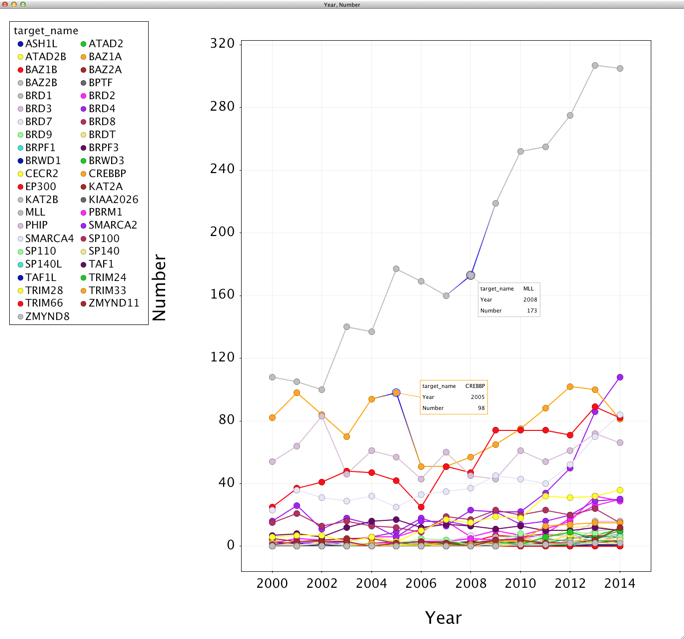
A new workspace is then created that contains the following table
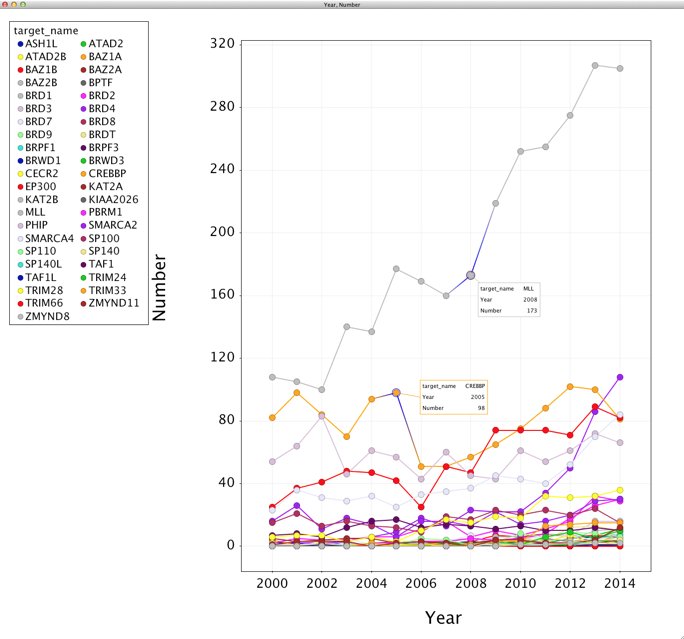
and a scatter plot, which at the moment is not very informative.
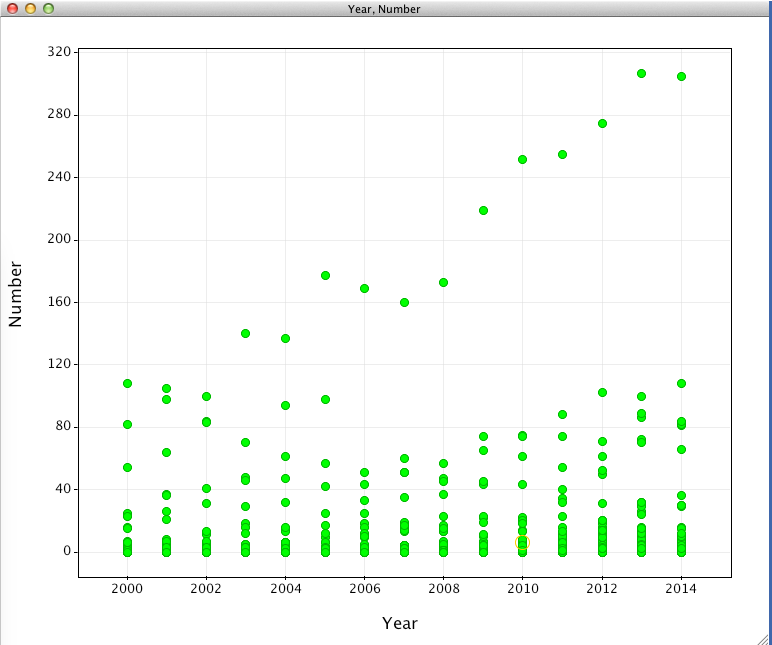
In the plot settings under “Columns” set colour to “targetname” category. In the “Display” tab, set the checkboxes to Display lines and points, Group Lines by targetname and change the line width to taste.
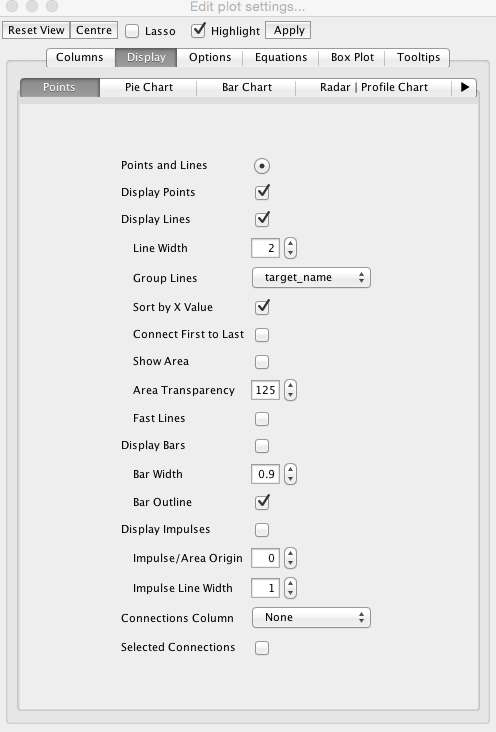
In the “Options” tab set the legend position to Top Left, and in the “Tooltips” tab choose target_name, year and number.
The script can be downloaded from here
Updated script can be downloaded here
Page Updated 31 March 2018