A recent paper on ChemRxiv https://chemrxiv.org/doi/10.26434/chemrxiv-2025-9c1v6 describes ANNalog a transformer-based sequence-to-sequence generative model trained on pairs of molecules extracted from the same bioactivity assay in
Category: Jupyter Notebook
I’ve written several posts on the various options for clustering molecules https://macinchem.org/?s=clustering and a recent post from NVIDIA described GPU-Accelerated Clustering with nvMolKit that uses
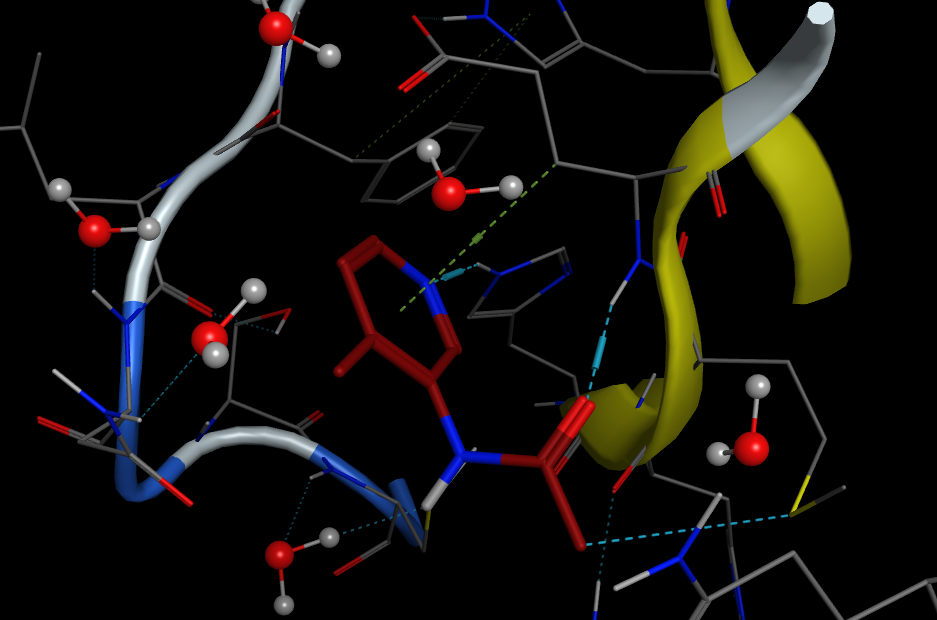
In 2020 as a result of lockdown I was asked to help create a course for MRes students as an introduction to computer-aided drug design.
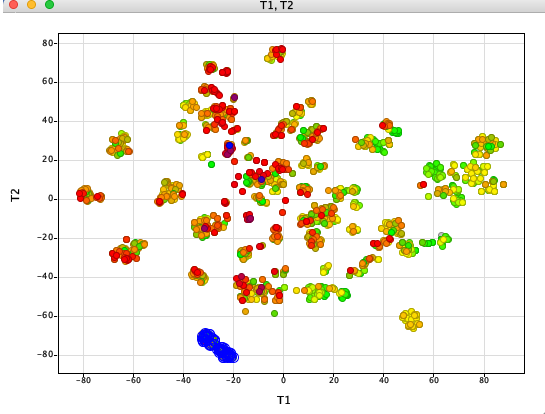
t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map. Whilst there are
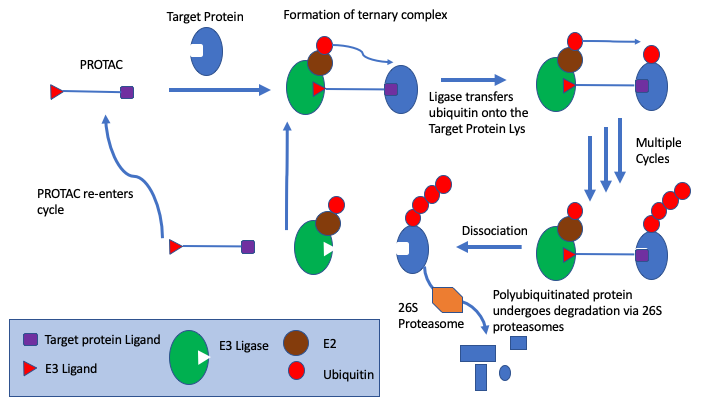
PROteolysis TArgeting Chimeras (PROTACs) technology provides an alternative to module biological function by specially using the ubiquitin proteasome system to induce degradation of the target
CNotebook provides chemistry visualization for Jupyter Notebooks and Marimo using the OpenEye Toolkits. Import the package and your molecular data will automatically render as chemical
MolView – SMILES Preview is a Visual Studio Code extension that renders SMILES (Simplified Molecular Input Line Entry System) strings as molecular structure diagrams on
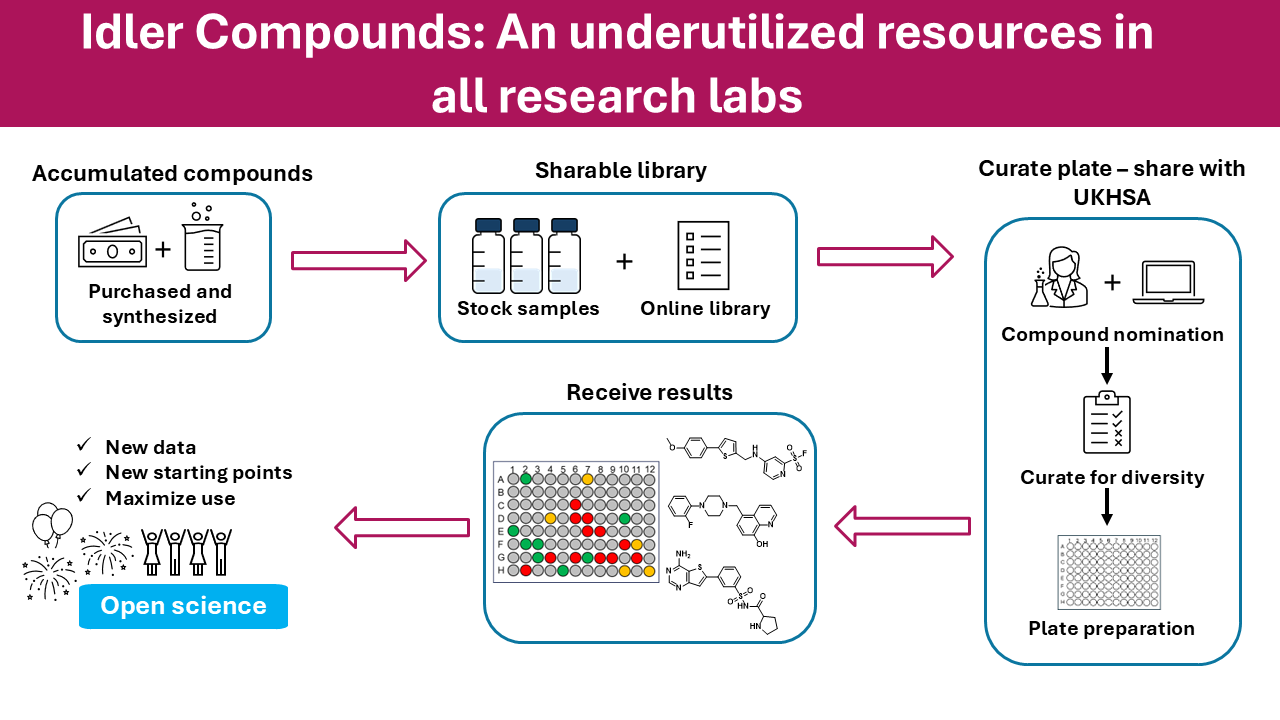
There was an interesting publication from the Todd group at UCL on Chemrxiv “Idler Compounds: A Simple Protocol for Openly Sharing Fridge Contents for Cross-Screening”
Apple just posted preprint on arxiv describing a new protein structure prediction tool SimpleFold https://arxiv.org/pdf/2509.18480. All code is available on GitHub https://github.com/apple/ml-simplefold including a simple
I’ve written a comparison of various clustering tools including BitBirch. A recent preprint [DOI] has illustrated BitBIRCH Clustering Refinement Strategies. In this Application Note we