A recent publication described “The Blood–Brain Barrier (BBB) Score” DOI a scoring function to determine the likelihood of a molecule being brain penetrant.
The blood–brain barrier (BBB) protects the brain from the toxic side effects of drugs and exogenous molecules. However, it is crucial that medications developed for neurological disorders cross into the brain in therapeutic concentrations. Understanding the BBB interaction with drug molecules based on physicochemical property space can guide effective and efficient drug design. An algorithm, designated “BBB Score”, composed of stepwise and polynomial piecewise functions, is herein proposed for predicting BBB penetration based on five physicochemical descriptors: number of aromatic rings, heavy atoms, MWHBN (a descriptor comprising molecular weight, hydrogen bond donor, and hydrogen bond acceptors), topological polar surface area, and pKa. On the basis of statistical analyses of our results, the BBB Score outperformed (AUC = 0.86) currently employed MPO approaches (MPO, AUC = 0.61; MPO_V2, AUC = 0.67). Initial evaluation of physicochemical property space using the BBB Score is a valuable addition to currently available drug design algorithms.
The algorithm is described in detail and the authors are commended for providing supplementary informations describing all the molecules used in the analysis and with SMILES strings, the calculated properties used in the statistical analysis together with the BBBscore.
I’m often working on drugs targeting the CNS so it seemed a good idea to implement it as a Vortex script. Vortex is an interactive data visualization and analysis solution for scientific decision support that is scientifically aware providing native cheminformatics and bioinformatics analysis and visualizations.
The Vortex Script
The first part of the script uses the ChemAxon command line tool to calculate a number of physiochemical properties needed for the algorithm, the resulting output is parsed, columns created and added to the workspace table.
The BBBScore is calculated, for each molecule the appropriate calculated properties are taken from the row, then the scoring logic is applied to determine the BBBscore and this column is populated.
# Created by http://www.macinchem.org
#THE BLOOD-BRAIN BARRIER (BBB) SCORE
#Mayuri Gupta, Hyeok Jun Lee, Christopher J. Barden, and Donald F. Weaver
#DOI: 10.1021/acs.jmedchem.9b01220
import sys
# Uncomment the following 2 lines if running in console
#vortex = console.vortex
#vtable = console.vtable
sys.path.append(vortex.getVortexFolder() + '/modules/jythonlib')
import subprocess
#Results go in here
colabnz= vtable.findColumnWithName('abzn', 1)
#Makes the column a string type
colabnz.setType(com.dotmatics.vortex.Vortex.STRING)
# Get the path to the currently open sdf file
sdfFile = vortex.getFileForPropertyCalculation(vtable)
# http://www.chemaxon.com/
# Run evaluate on the file
p = subprocess.Popen(['/Applications/MarvinSuite/bin/evaluate', sdfFile, '-g', '-e', "logp(); logd('7.4'); apka('1'); bpka('1'); atomCount(); mass(); acceptorcount(); donorcount(); topologicalPolarSurfaceArea(); atomCount()-atomCount('1');aromaticRingCount();aromaticAtomCount()/(atomCount()-atomCount('1'))"], stdout=subprocess.PIPE)
output = p.communicate()[0]
# Create new columns in table if needed
cols = "logP;logD;apKa;bpKa;atomCount;mass;HBA;HBD;TPSA;HAC;aromaticRingCount;FractionAromatic"
colName = cols.split(';')
for c in colName:
column = vtable.findColumnWithName(c, 1, 1)
vtable.fireTableStructureChanged()
lines = output.split('\n')
keys = []
for i in lines:
words = i.split(';')
if len(words) == 2:
keys.append(words[0])
# Parse the output
rows = lines[0:len(lines)]
for r in range(0, vtable.getRealRowCount()):
vals = rows[r].split(';')
for j in range(0, len(vals)):
column = vtable.findColumnWithName(colName[j], 0)
column.setValueFromString(r, vals[j])
# Calculate abnz
# check if there is no pka
colapka = vtable.findColumnWithName('apKa', 0)
colbpka = vtable.findColumnWithName('bpKa', 0)
rows = vtable.getRealRowCount()
for r in range(0, int(rows)):
apkaExists = colapka.isDefined(r)
bpkaExists = colbpka.isDefined(r)
if apkaExists is True:
taskaID = colapka.getValue(r)
if taskaID <7.0:
aScore=1
elif taskaID > 7.0:
aScore = 0
elif apkaExists is False:
aScore = 0
if bpkaExists is True:
taskbID = colbpka.getValue(r)
if taskbID >7.5:
bScore=1
elif taskbID < 7.5:
bScore = 0
elif bpkaExists is False:
bScore = 0
if aScore == 1 and bScore == 1:
TheScore = 'Zwitterion'
elif aScore == 1 and bScore == 0:
TheScore = 'Acid'
elif aScore == 0 and bScore == 1:
TheScore = 'Base'
elif aScore == 0 and bScore == 0:
TheScore = 'Neutral'
column = vtable.findColumnWithName('abzn', 1)
column.setValueFromString(r, TheScore)
#BBBScore
#Ar ring score
colArRC = vtable.findColumnWithName('aromaticRingCount', 0)
colHAC = vtable.findColumnWithName('HAC', 0)
colMW = vtable.findColumnWithName('mass', 0)
colHBA = vtable.findColumnWithName('HBA', 0)
colHBD = vtable.findColumnWithName('HBD', 0)
colTPSA = vtable.findColumnWithName('TPSA', 0)
rows = vtable.getRealRowCount()
for r in range(0, int(rows)):
taskarID = colArRC.getValue(r)
if taskarID == 0:
arScore = 0.336376
elif taskarID == 1:
arScore = 0.816016
elif taskarID == 2:
arScore = 1
elif taskarID == 3:
arScore = 0.691115
elif taskarID == 4:
arScore = 0.199399
elif taskarID > 4:
arScore = 0
taskHACID = colHAC.getValue(r)
if taskHACID < 6:
HACscore = 0
elif taskHACID > 45:
HACscore = 0
else:
HACscore = (1/0.624231)*(0.0000443*taskHACID ** 3-0.004556*taskHACID ** 2+0.12775*taskHACID-0.463)
taskTPSAID = colTPSA.getValue(r)
if taskTPSAID == 0:
TPSAscore = 0
elif taskTPSAID > 120:
TPSAscore = 0
else:
TPSAscore = (1/0.9598)*(-0.0067*taskTPSAID+0.9598)
taskMW = colMW.getValue(r)
taskHBA = colHBA.getValue(r)
taskHBD = colHBD.getValue(r)
MWHBN = (taskMW) ** (-0.5) * (taskHBA+taskHBD)
if MWHBN <= 0.05:
MWHBNscore = 0
elif MWHBN > 0.45:
MWHBNscore = 0
else:
MWHBNscore = (1/0.72258)*(26.733*MWHBN ** 3-31.495*MWHBN ** 2+9.5202*MWHBN-0.1358)
apkaExists = colapka.isDefined(r)
bpkaExists = colbpka.isDefined(r)
taskaID = colapka.getValue(r)
taskbID = colbpka.getValue(r)
if taskbID >= 5:
pka = taskbID
elif taskbID < 5 and apkaExists is True and taskaID <= 9:
pka = taskaID
else:
pka = 8.81
pkascore = 0.000
if pka <= 3:
pkascore = 0
elif pka > 11:
pkascore = 0
else:
pkascore = (1/0.597488)*(0.00045068*pka**4-0.016331*pka**3+0.18618*pka**2-0.71043*pka+0.8579)
BBB_Score = arScore + HACscore + (1.5*MWHBNscore) + (2*TPSAscore) + (0.5*pkascore)
colBBB = vtable.findColumnWithName('BBBScore', 1, vortex.DOUBLE)
colBBB.setDouble(r, BBB_Score)
Comparison with Supplementary Information Data
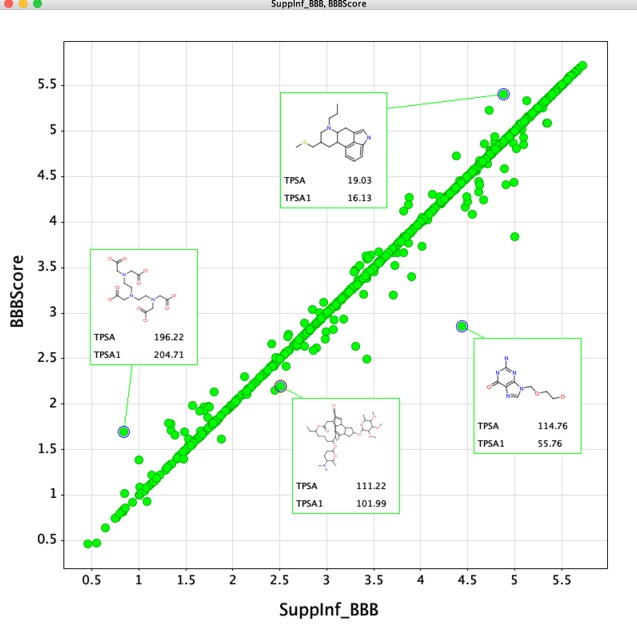
The data for over 1000 examples is provided in the supplementary information, this includes both CNS penetrant and non-penetrant compounds. The plot below compares the data from the supplementary information (SuppInf_BBBscore) with the data calculated for this implementation in the Vortex script. Whilst overall there is good agreement there appear to be a few outliers. On closer investigation many of the differences appear to be due to differences in the calculated TPSA. Since both implementations use the same ChemAxon software it is possible that updated version (I used version 19.8.0) has resulted in the differences.
The script can be downloaded here
It requires access to the ChemAxon evaluate tool.
Last updated 5 December 2019