This is the new hosting for the Macs in Chemistry website. It is still under construction so there is currently incomplete content. We will be
Blog
The next Cambridge Cheminformatics Meeting – on 8 May 2024, 4pm UK time; Hybrid, at the CCDC and on Zoom! Full details are on the
This looks very useful for anyone having to process multiple molecules, I particularly like the error processing! The open-source package scikit-learn provides various machine learning
tmap is a very fast visualisation library for large, high-dimensional data sets. It was published in 2020 DOI and the code is available on GitHub
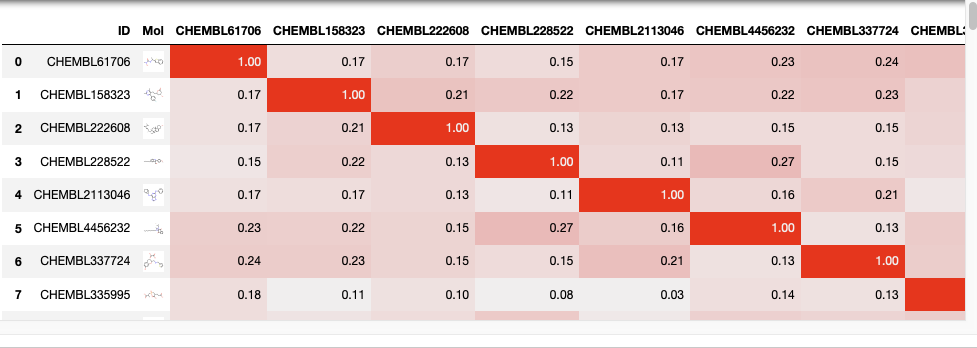
I’m sometimes asked for a tool to compare the similarity of a list of molecules with every other molecule in the list. I suspect there
Interesting paper on Biorxiv https://www.biorxiv.org/content/10.1101/2023.09.27.559736v1.full.pdf We propose a method dedicated to finding antibodies in cryo-EM densities : CrAI. This machine learning method leverages the conserved structure
The Apple worldwide developer conference is on June 10–14, 2024. Whilst there is likely to be updates to Apple hardware and OS, given the recent
A new Apple preprint has appeared on Arxiv. https://arxiv.org/pdf/2403.20329.pdf Reference resolution is an important problem, one that is essential to understand and success- fully handle
(1) Added TeraChem support last week, meaning you can now run GPU-accelerated DFT calculations. (Read more about TeraChem + Rowan here.) (2) Rowan now has tautomer + conformer
Everyone’s favourite text editor has been updated, the release notes are here https://www.barebones.com/support/bbedit/current_notes.html BBEdit 15 requires Mac OS X 11.0 or later. For whichever version
An excellent brief introduction to PyMOL 3.0.